Introduction
By Jiayi Wu updated on Feb 2020
A more natural way to learn Chinese
Our goal is to develop an natural curriculmn for Chinese. Learning Chinese is difficult: one needs a vocabulary of more than 2000 characters to read a newspaper. Popular language apps begin with groups or phrases of words in English and then tries to teach you the translated Chinese. This ultimately becomes a memorization task between two language systems that are completely different.

However, this can be improved if you think about how Chinese was created. While English is phonetic, the meanings of Chinese characters are rather linked to their composing logograms. Simple characters were created first, then compound words were made from combining these basic components.

How can machine learning help?
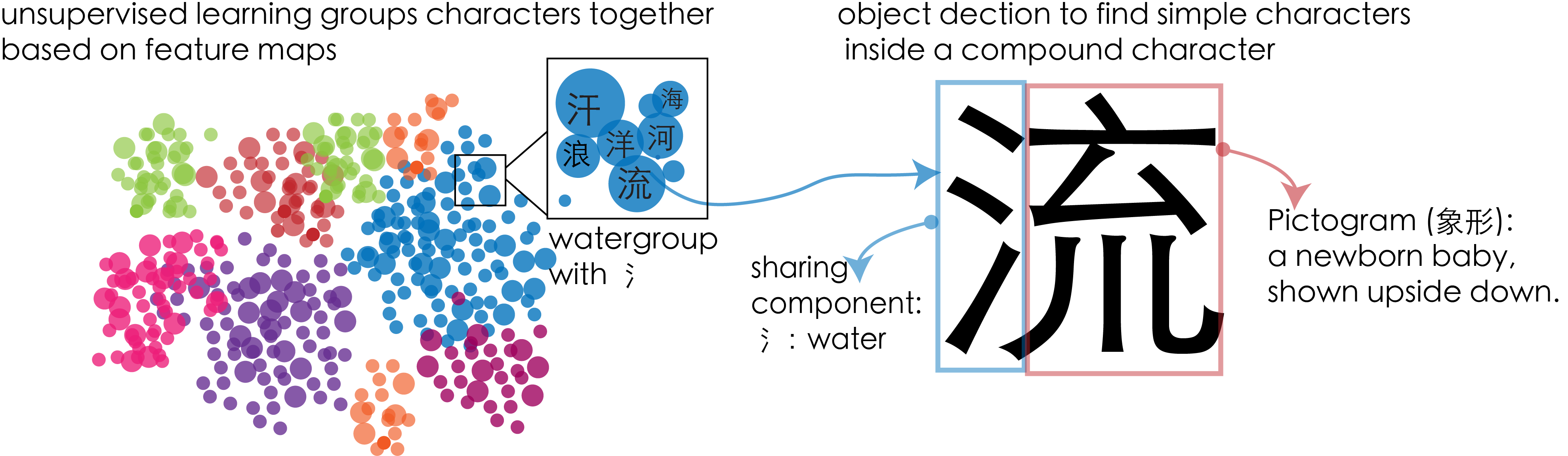
How do you find linkages between characters through these simple elements? Luckily, we don’t have to draw the connections by hand: we can use modern machine learning techniques! In this project, I extracted the features of characters using a convolutional neural network and used unsupervised learning algorithms to group the characters by their common parts.
On this map, characters that share basic logograms are clustered together. One can use this map as a basic starting point in developing curriculums for Chinese. A student can begin with the groupings at the smallest scale and make their way up!
Click the below link to access the application to start learning!
What else we can do?
Results like this will dramatically decrease the amount of memorization needed to learn Chinese. This process can not only be applied Chinese but also to many logogram based languages, even ones without a dictionary. For example, we can use these machine learning techniques to decipher ancient languages such as Mayan!
{kind=link}
Check out this nice map from Wikipedia with all the logogram-based languages arranged in the world: here.
{kind=link}